
Memory consistency model and Cache coherence
内存一致性模型与缓存一致性的关系
刚开始接触缓存一致性以及内存一致性模型的时候,时常会对其产生误解,对两者的概念比较模糊,在这里借用《A Primer on Memory Consistency and Cache Coherence》中的介绍来对其进行区分。
该书中使用SWMR(Single Writer Multiple Reader)不变量以及数据值(Data Value)不变量来定义缓存一致性,前者指的是对于同一时刻,同一个内存地址,要么只有一个核心对其拥有读写权限,要么有零个或者多个对于该地址只有只读权限。而后者则指的是,任何对于内存的修改都会被传播给其他副本,以至于副本保存的总是其最新的值。
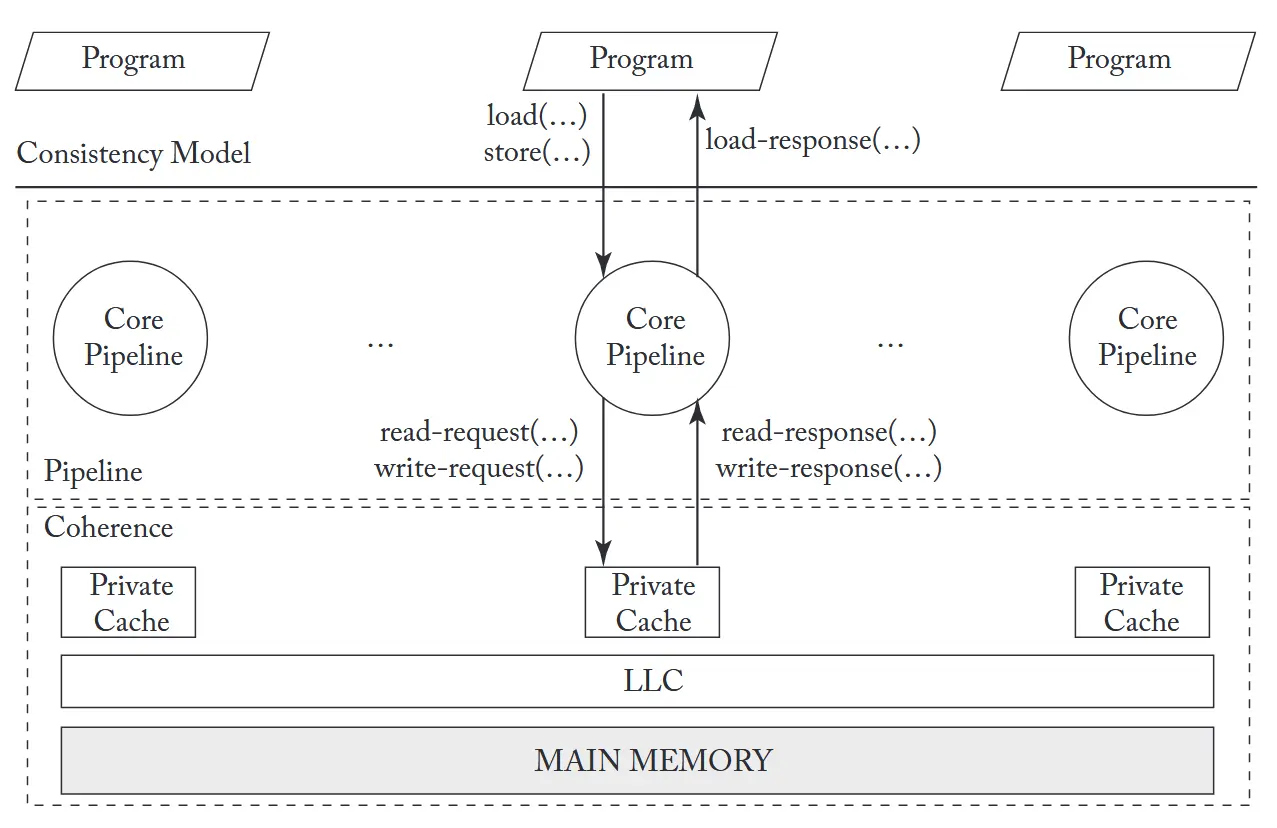
而内存一致性(模型)则是定义在缓存一致性之上的,程序员需要依据内存一致性模型来编写出正确的多线程程序,而缓存一致性主要是为处理器流水线提供一个存储系统的抽象层,对于程序员来说时透明的,如下图所示:
Summary
- Cache coherence于Memory consistency并不等效
- Memory consistency的具体实现可以将Cache coherence作为一个有用的黑盒
除此之外,依据缓存一致性于内存一致性模型之间是否能够被清晰地划分开来,可以将缓存一致性协议分为两类:
- Consistency-agnostic coherence:在第一类协议中,一个写操作在返回之前就已经对所有其他内核可见。由于写操作是同步传播的,这类协议提供的接口与无缓存的原子内存系统完全一致。因此,任何与一致性协议交互的子系统——例如处理器核心流水线——都可以假设自己在与一个没有缓存的原子内存系统交互。从一致性保证的角度看,这种一致性接口带来了良好的“关注点分离”。缓存一致性协议完全屏蔽了缓存的存在,呈现出仿佛缓存被移除、只有主存位于一致性盒子中的原子内存假象(见上图),而处理器核心流水线负责执行一致性模型中规定的所有排序要求。
- Consistency-directed coherence:在第二类(较新的)协议中,写操作异步传播——即一个写操作可以在尚未对所有处理器可见之前就返回,因此其他处理器在真实时间上有可能观察到过期(stale)的值。然而,为了正确实现内存一致性,这类协议必须保证最终对外可见的写入顺序严格遵循一致性模型规定的排序规则。回到上图的抽象模型,这种类型中流水线与一致性协议共同负责执行一致性模型规定的排序要求。这类协议最初为提高通用 GPU(GP-GPU)的吞吐量而出现。
Note
基于我个人的理解而言,缓存一致性指的是同一个地址的数据存在多个本地的备份,其中一个备份被修改了,其他的备份需要知道。
而内存一致性(模型) 更多的是一种约定,描述了该多核处理器对于不同地址数据进行访问时,不同核心所看到的执行顺序并不一样。
缓存一致性介绍
在现代的多核系统中,为了弥补主存与处理器速度之间的差距,通常会在每个处理器核心上配备一个或多个级别的缓存(Cache)。而缓存的核心作用就是为处理器提供其所需数据的高速备份,从而提高整体系统的性能。然而,当多个处理器核心同时访问和修改共享数据时,同一个数据就会存在多个备份,当其中一个备份的数据被其对应的处理器修改之后,另一个备份并不知情,这就会导致不同处理器看到的数据是不一致的,从而引发一系列的问题。
如下所展示的一个简单的缓存一致性问题的例子:假设全局变量A的初始值为0,且仅处于主存当中。
- CPU1读取变量A的值,触发cache miss,从主存中将A的值(0)加载到自己的缓存中。
- CPU4读取变量A的值,触发cache miss,从主存中将A的值(0)加载到自己的缓存中。
- CPU4将变量A的值修改为4,这时候有两者情况,如果是写回(write back)策略,则仅仅是将A的cache值修改为4,并且标记该缓存行为“脏”(dirty),此时主存中的A的值仍然是0;如果是写穿(write through)策略,则不仅将A的cache值修改为4,主存中的A的值也会被更新为4。
- CPU1再次读取变量A的值,这时候如果没有任何缓存一致性协议的介入,CPU1将会继续读取到自己缓存中的A的值0,而不是最新的值4。
经过上述四步之后,全局的共享变量A,在不同位置上的值如下图所示:
graph TB
subgraph CPUs
CPU1((CPU1))
CPU2((CPU2))
CPU3((CPU3))
CPU4((CPU4))
end
Cache1[Cache
A=0]
Cache2[Cache]
Cache3[Cache]
Cache4[Cache
A=4]
Bus[===== BUS =====]
Mem["Main Memory
A=0 (write back)
or 4 (write through)"]
CPU1 --- Cache1
CPU2 --- Cache2
CPU3 --- Cache3
CPU4 --- Cache4
Cache1 --- Bus
Cache2 --- Bus
Cache3 --- Bus
Cache4 --- Bus
Bus --- Mem
Note1[/"1. read A
4. read A"/]
Note2[/"2. read A
3. write A=4"/]
Note1 -.-> CPU1
Note2 -.-> CPU4
而由上述的缓存一致性问题,又会导致程序不按照预想的逻辑运行。
例如有如下一个程序,其有两个线程, 分别被安排在CPU1和CPU2上运行。
1 | int flag = 0; |
对于该程序,我们的期望逻辑是:thread2一直等待,直到thread1将数据data准备好,并且将标志位flag置为之后,thread2才会继续执行并打印出数据data的值。
但是如下流程图所示,由于缓存一致性问题,thread2可能永远看不到flag被置为1的操作,从而导致它一直处于自旋等待的状态,永远无法打印出数据data的值。
sequenceDiagram
autonumber
participant CPU1 as CPU1 / thread1
participant C1 as CPU1 Cache
participant MEM as Main Memory
participant C2 as CPU2 Cache
participant CPU2 as CPU2 / thread2
Note over CPU1,CPU2: 初始:flag=0, data=0
%% CPU2 先开始自旋读取 flag(操作1)
CPU2->>C2: load flag
alt 第一次访问,miss
C2->>MEM: read flag
MEM-->>C2: flag = 0
end
C2-->>CPU2: flag = 0
loop while(flag == 0)
CPU2->>C2: load flag
Note right of C2: CPU2 一直命中本地 cache,
读取到的都是旧值 flag=0
C2-->>CPU2: flag = 0
end
%% 另一方面,CPU1 执行写 data=1, flag=1
CPU1->>C1: store data = 1
Note right of C1: data=1 写入 CPU1 的 cache,
可能稍后再写回内存
CPU1->>C1: store flag = 1
Note right of C1: flag=1 也只更新在 CPU1 cache 中,
没有触发对 CPU2 cache 的失效/更新
C1->>MEM: write-back (可选) data=1, flag=1
Note over C1,MEM: 即使内存已是 1,
但 CPU2 的 cache 里 flag 仍是 0
%% 因为没有 cache coherence,CPU2 永远看不到 flag=1
loop while(flag == 0) 继续自旋
CPU2->>C2: load flag
C2-->>CPU2: flag = 0
end
Note over CPU2: CPU2 一直认为 flag==0,
甚至永远无法执行 printf
从上述的两个例子中,我们不难看出缓存一致性的重要性,而为了解决缓存一致性的问题,当前主要有两种解决方案:总线嗅探(snopping-based)方案和目录式(Directory-based)方案。
Snoopying-based方案: 每个缓存控制器都会监听(嗅探)总线上的所有读写请求,当某个处理器对某个地址发起读写请求时,其他缓存控制器会检查自己是否缓存了该地址的数据,如果缓存了,则根据请求的类型(读或写)采取相应的操作,例如无效化自己的缓存行或者更新自己的缓存行,从而确保所有缓存中的数据是一致的。
Directory-based方案: 每个内存块都有一个目录,记录了哪些缓存中存储了该内存块的副本。当某个处理器需要访问某个内存块时,它会先查询目录,目录会告诉它哪些缓存中有该内存块的副本,然后处理器可以直接与这些缓存进行通信,确保数据的一致性。这种方案通常适用于大规模多处理器系统,因为它减少了总线上的通信量。
内存一致性模型介绍
内存一致性模型(Memory Consistency Model)定义了在多处理器系统中,多个处理器对共享内存的读写操作的可见性和顺序性规则。它规定了一个处理器对内存的写操作何时对其他处理器可见,以及多个处理器对同一内存位置的读写操作之间的顺序关系。
仍然拿上面的缓存一致性的例子来介绍内存一致性,其程序如下所示:
1 | int flag = 0; |
对于该程序,如果存在缓存一致性问题,则thread2可能一直在自旋,导致无法打印出数据data的值。但是是不是如果没有缓存一致性问题,该程序就能按照预期来工作呢?答案是否定的。
我们可以假设缓存一致性的问题已经解决了或者假设两个CPU没有缓存,为了简单,我们就假设系统为一个多核无缓存的系统,其系统框图如下:
graph TB
subgraph CPUs
CPU1((CPU1))
CPU2((CPU2))
CPU3((CPU3))
CPU4((CPU4))
end
Bus[===== BUS =====]
Mem["Main Memory"]
CPU1 --- Bus
CPU2 --- Bus
CPU3 --- Bus
CPU4 --- Bus
Bus --- Mem
Note1[/"1. data = 1
2. flag = 1"/]
Note2[/"3. while(flag == 0)
4. print data"/]
Note1 -.-> CPU1
Note2 -.-> CPU4
在不考虑所谓的内存一致性模型的前提下,我们对于上述程序的期望就是最终输出1。但是实际上,基于该CPU的内存模型,程序最终既可能输出1,也可能输出0。
其根本原因在于,对于CPU4而言,其可能先看到flag = 1,然后才看到data = 1。但是这并不是错误,而是由CPU的设计与实现方案所导致的。究其原因,其主要还是由于当代CPU为了提升性能,通常会重排序内存访问(Reorder Memory Accesses),即允许处理器在执行内存操作时,不严格按照程序中指令的顺序进行,而是根据数据依赖关系和硬件资源的可用性,动态调整内存操作的执行顺序。而上述输出0的情况,就是由于store-store reordering所导致的(CPU1中的S1与S2 reorder)。
而内存一致性模型的作用就是用于规范多线程程序的访存行为,从而使得程序能够按照预期的逻辑来运行。
CPU存在哪些可能的内存访问重排序?
尽管现代内核可能对许多内存访问进行重排序,但我们只需要考虑两个内存操作的重排序就足够了。多数情况下,我们只需讨论内核针对两个不同地址的内存操作进行重排序的情形,因为顺序执行模型(即冯·诺依曼模型)通常要求对同一地址的操作必须按程序原有顺序执行。我们根据被重排序的内存操作是加载(load)还是存储(store),将可能的重排序情况分为三类。
- store-store reordering: 如果一个核心有一个非FIFO的写缓存区(store buffer), 那么它可能会允许store-store重排序。也就是说,后面的store操作可能会比前面的store操作更早地被提交到内存系统中。需要注意的是,即使核心是按照程序的顺序执行的,这种重排序仍然可能发生。而对于单线程来说,对不同地址的store操作进行重排序是没有影响的。
- load-load reordering: 当代的动态调度核心可能会按照不同的顺序执行指令。以上面的程序为例,CPU2可能会对
L1和L2进行重排序,因为对于单线程来说,这样的重排序是没有影响的。但是对于多线程,这种排序可能会导致L2、S1、S2、L1的执行顺序,从而导致输出是0。 - load-store and store-load reordering: 乱序核心也可以重新排序来自同一线程的加载和存储(针对于不同地址的加载和存储),从而导致不确定的结果
store-load 重排序示例
下面的程序展示了store-load重排序的一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14int x = 0, y = 0;
int r1 = 0, r2 = 0;
// run on CPU1
void thread1() {
x = 1; // S1
r1 = y; // L1
}
// run on CPU2
void thread2() {
y = 1; // S2
r2 = x; // L2
}
上述程序的可能的输出结果:
- (r1 == 1, r2 == 1)—— 执行顺序为 S1, S2, L1, L2
- (r1 == 0, r2 == 1)—— 执行顺序为 S1, L1, S2, L2
- (r1 == 1, r2 == 0)—— 执行顺序为 S2, L2, S1, L1
- (r1 == 0, r2 == 0)—— 执行顺序为 L1, L2, S1, S2
其中最后一个结果就是由于store-load重排序所导致的。
内存一致性模型分类
顺序一致性(Sequential Consistency, SC)
SC模型最早由Lamport提出,SC定义每个单独的核心的执行顺序(访存顺序)必须按照程序指定的顺序执行,但是不同核心之间的全局执行顺序(访存)可以是任意的。
Note
需要注意的是,在SC模型当中,不同核心看到的内存操作顺序应该是一致的。
如下执行流程图(以上面的代码为例)显示怎么样才算是符合SC模型的执行流程的:
sequenceDiagram
participant P1 as Program Order {p} of Core C1
participant M as Memory Order {m}
participant P2 as Program Order {p} of Core C2
%% ===================== (a) SC Execution 1 =====================
rect rgb(240,255,255)
autonumber 1
Note over P1,P2: (a) SC Execution 1
Outcome: (r1, r2) = (0, 1)
P1->>M: S1: x = 1
P1->>M: L1: r1 = y
P2->>M: S2: y = 1
P2->>M: L2: r2 = x
end
%% ===================== (b) SC Execution 2 =====================
rect rgb(240,240,255)
autonumber 1
Note over P1,P2: (b) SC Execution 2
Outcome: (r1, r2) = (1, 0)
P2->>M: S2: y = 1
P2->>M: L2: r2 = x
P1->>M: S1: x = 1
P1->>M: L1: r1 = y
end
%% ===================== (c) SC Execution 3 =====================
rect rgb(240,255,240)
autonumber 1
Note over P1,P2: (c) SC Execution 3
Outcome: (r1, r2) = (1, 1)
P1->>M: S1: x = 1
P2->>M: S2: y = 1
P1->>M: L1: r1 = y
P2->>M: L2: r2 = x
end
%% ===================== (d) NOT an SC Execution =====================
rect rgb(255,240,240)
autonumber 1
Note over P1,P2: (d) NOT an SC Execution
Outcome: (r1, r2) = (0, 0)
%% 这里先按程序顺序画事件
P2->>M: L2: r2 = x
P1->>M: S1: x = 1
P1->>M: L1: r1 = y
P2->>M: S2: y = 1
end
其中前三个就是符合SC模型的执行流程,因此在SC模型的CPU下,该三个结果都是正确的,但是第四个则不是。
SC模型的优势就是简单,但是其缺点也很明显,那就是性能较低,因为SC模型限制了处理器对内存操作的重排序能力,从而限制了处理器的优化空间。所以先打处理器的内存模型基本都偏离了SC模型。
放宽的内存一致性模型(Relaxed Consistency Models)
上述的SC模型严格地限制了store-load、store-store、load-load和load-store这四种内存读写的重排序(即使这些操作之间没有控制、数据和流水线上面的依赖)。
而宽松内存模型(Relaxed Consistency Models) 的关键思想是允许乱序执行store和load操作,而依据具体放宽松了哪一对store和load的操作,可以将其分为如下几种类型:
- Total Store Order (TSO): 允许
store-load重排序,但禁止store-store、load-load和load-store重排序(引入fifo属性的store buffer就会导致这种情况)。 - Partial Store Order (PSO): 允许
store-load和store-store重排序,但禁止load-load和load-store重排序(引入非fifo属性的store buffer就会导致这种情况)。 - Relaxed Memory Order (RMO): 允许所有四种类型的重排序。
Note
这些顺序放松但依旧保证了在本CPU与程序代码一致的存取顺序,但在其它CPU节点看来顺序就可能被打乱了。
TSO模型示例
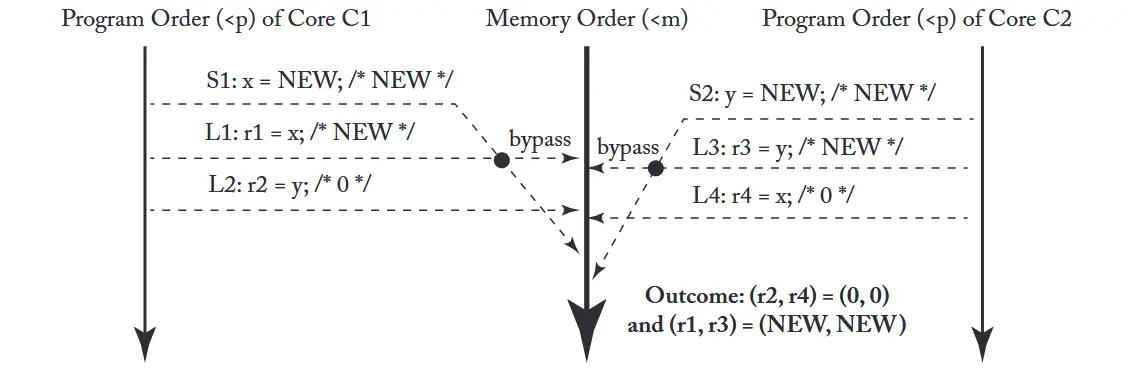
如下一个示例展示了,对于同一个线程来说,其看到的内存顺序是没有重排序的,但是对于另一个线程来说,其看到的则是store被延后到load后面了。
1 | int x = 0; |
在TSO模型下,很多人可能认为最终会出现(r1, r2, r3, r4) = (0, 0, 0, 0)的结果。但是事实上并不会,这是因为r1和r3 load的是本地CPU的值,因此会使用Write Buffer Bypass机制,直接从Write Buffer中读取到最新的值1,因此r1与r3的值最终都会是1。产生这种结果的执行流程图如下图所示。
再来看另一个例子:
1 | int a = 0; |
对于这个例子,如果thread3看到的结果是(a, b) = (1, 0),那么thread4看到的结果就不可能是(a, b) = (0, 1)。因为在TSO模型下,store-store操作是不能重排序的,因此S1必须在S2之前被提交到内存中,从而使得thread4不可能看到b = 1而a = 0的结果。
Note
从这个例子当中,可以看出来,如果允许load-load重排序的话,那么最终就会导致不同线程看到完全不一样的顺序,内存模型就会很复杂。